Incremental Gambits and Premature Endgames
In chess, there are three phases to the game, all with distinct strategies: the opening, the middlegame, and the endgame. In the opening, the first 15 or so moves of the game, the goal is to deploy your pieces from their starting positions and control the center of the board. The middlegame involves back-and-forth offense and defense as players target each other’s pieces via tactics and attempt to checkmate the king. The endgame begins when most pieces have been captured without a checkmate. Only a few pieces remain, and a slower, mathematical trudge begins to checkmate the king and declare victory.
Plenty of cliche parallels exist between chess and business, but nowhere do I find them more relevant than in the current AI race. The progression has been:
- Opening (2017-2022): Researchers and companies developed models based on the transformer architecture, setting the pieces on the board.
- Middlegame (2022-2024): ChatGPT blew the center wide open. It sparked rapid-fire iteration and fierce competition, with companies racing to deploy applications built on top of LLMs.
- Endgame (Today): A handful of dominant players—chip designers, data center suppliers, hyperscalers, and top model houses—have consolidated power and are fighting to maintain their leads.
The status quo assumes that the transformer architecture will win. Companies up and down the stack have coalesced around transformers thanks to their generalizability and scalability. Consolidation has led to an innovation landscape dominated by incremental gambits – clever little hacks meant to squeeze more juice out of models without fundamentally advancing their intelligence.
We’ve prematurely entered the endgame of the AI wave, crowning a winning technology before getting the chance to deploy all of our pieces. This essay will examine the limitations of our current approach and propose alternatives that may lead us closer to superintelligence. As it stands, we risk a stalemate – trapped in a local optimum lacking the fundamentals to unlock AGI.

The Old King
Attention is All You Need introduced the transformer in 2017. Its self-attention mechanism allows the model to capture contextual relationships between words more efficiently. In 2018, Google released BERT, which introduced bi-directional pre-training. A massive, plain text dataset was used to train the model before fine-tuning it to a specific task. This helped influence the development of OpenAI’s GPT models, which were trained on large corpora of text (and later other multi-modal data) and demonstrated impressive zero-shot learning capabilities. When ChatGPT was released in November 2022, the transformer went mainstream and started the race to build around it.
These early successes paved the way for the ubiquity of transformers across AI. The transformer’s ability to scale effectively, capture long-range dependencies, and adapt to various language-based tasks has made them the go-to architecture across textual domains, including less obvious areas like biology and chemistry. Today, companies like OpenAI (GPT), Meta (Llama), Anthropic (Claude), xAI (Grok), and more are all-in on transformers and pushing the boundaries of performance.
Despite the success, transformers feel like they’re starting to reach their limits. While models incrementally improve with each iteration, it has become apparent that the path to AGI is far from clear using transformers alone. LLM performance gains are becoming increasingly difficult to achieve due to their insatiable appetite for training data and compute. The most advanced models struggle with complex reasoning tasks that require multi-step logical inference or abstract thinking. LLMs often fail to generalize knowledge in novel ways, relying on pattern-matching within their training data rather than demonstrating proper cognitive understanding. Realistically, superintelligence is unlikely to emerge out of this architecture.
While transformers have completely upended consumer and enterprise workflows, they won’t be the final step toward AGI (and not even SOTA within a few short years). The utopian hype following the release of ChatGPT has waned as expectations inflate. I’ll explore these challenges in the following sections, examining why transformers fall short in crucial areas like reasoning, generalization, and efficient scaling. We’ll also look at other approaches that address these fundamental issues and offer alternative endgames on the march toward AGI.
Incremental Gambits
At the heart of the transformer lies its fundamental challenge (ironically caused by its greatest strength): the quadratic computational complexity problem caused by self-attention. This alone will prevent the transformer architecture from enabling AGI.
In a transformer, each token in a sequence must attend to every other token, resulting in a computational complexity that grows quadratically with input length. In other words, a sequence of length n results in n^2 computations. This means that doubling the length of an input doesn’t just double the computational requirements — it quadruples them. This kind of scaling poses a problem for training and inference, especially as we aim to process longer text sequences or incorporate multiple modalities. I won’t go into deeper detail about the mechanics, but you can find a tremendous technical writeup on self-attention here.
 Explainable AIL Visualizing Attention in Transformers (Comet)
Explainable AIL Visualizing Attention in Transformers (Comet)
The impact of quadratic complexity is evident in the limited context windows of current commercial models. For instance, despite having an estimated 1.7B+ parameters, GPT-4o has a context window of just 128K tokens — equivalent to about 300 pages of text. Quadratic complexity has spawned a wave of research aimed at solving it.
A gambit in chess is when a player sacrifices a piece during the opening in exchange for material compensation later. They are tricks meant to do more with less. I call these recent improvements to manage quadratic complexity incremental gambits because they offer marginal advantages over base transformers but often introduce new trade-offs while remaining inherently based on neural nets.
One popular approach has been the development of sparse attention mechanisms. Models like Longformer use patterns of sparse attention to reduce computational complexity by focusing on relationships between only a strategic subset of relevant tokens. While this allows for the efficient processing of much longer sequences, it can potentially miss critical long-range dependencies in data. Another tactic has been the exploration of linear attention mechanisms. These have shown that it’s possible to approximate the attention computation with linear operations. In turn, computational requirements are significantly reduced, but so is the expressive power of the model. Researchers have also experimented with recurrent memory techniques to extend the effective context of transformers. These allow the model to access a sizable external memory, enabling theoretically indefinite context length. However, this approach adds complexity without addressing the underlying transformer scaling issues.
This piece from Mackenzie Morehead offers a more detailed look at attention alternatives and helped inspire this section.
These gambits help make transformers (and neural nets broadly) better, but won’t actually get us closer to AGI. Through the lens of these approaches, the goal has shifted from making AGI to making transformers work, a divergence from OpenAI’s own charter. The question then becomes: “Why do we need to make transformers / neural nets work?”. I believe it’s because we’re in too deep already.
Premature Endgames
Chinchilla scaling laws refined our understanding of the optimal balance between model size and training data. The DeepMind research team found that many LLMs were undertrained relative to their size, suggesting that making models bigger wasn’t the most efficient path forward. This assertion starkly contrasted with the prevailing notions outlined in Kaplan’s scaling laws. As models grow, performance improvements become increasingly unpredictable and potentially disappointing, which explains why larger models have been perceived as underwhelming.
The transition from Llama-3 70B to Llama-3.1 405B illustrated this challenge well. Despite a nearly 6x increase in parameters, Llama-3.1 405B only scored 3.2 points better than Llama-3 70B on the 5-shot MMLU benchmark. This nominal improvement relative to the massive increase in model size, computational resources, and training time signals diminishing returns and raises serious questions about the viability of continued scaling as a path to AGI.
From a purely economic perspective, the trend has translated into a staggering capex problem that analysts expect will worsen, even with a delayed Blackwell GPU. The AI arms race has led to unprecedented investment in compute infrastructure, with companies betting on the assumption that larger models will justify the costs. However, the ROI remains highly questionable.
Private market arguments on this topic can be overly optimistic. Most concede that there is a demand issue but conclude that it will catch up and make investors whole. Some investment may be recouped, but this is a classic VC take that fails to capture the intricacies of how we’ll get there.
In a recent episode of BG2, Brad Gerstner and Bill Gurley offered a more pragmatic view through the lens of public markets.
There’s a growing concern that supply is outpacing demand. While Jensen estimates that $2T will need to be spent on data center build-out by 2028, it’s unclear if end-user demand will materialize to justify the massive capital outlay. At a projected 14% of market-wide capital spending by 2026, NVIDIA is expected to be “comparable to IBM at the peak of the Mainframe Era or Cisco, Lucent, and Nortel at the peak of the New Economy Era.” A foreboding interpretation of the tea leaves as NVIDIA slumps on an earnings beat as customers and investors realize it could be mortal after all…
Even consumer-facing AI applications are struggling to generate revenues commensurate with the hype. OpenAI expects to bring in $3.4B in 2024, a fraction of what’s needed to close the expanding air gap. There’s a noticeable disconnect between growing user bases and actual engagement metrics, raising questions about the long-term value proposition of these offerings.
There’s a misalignment between massive capex and uncertain future revenues. While big tech executives acknowledge that capex and revenues will never be perfectly aligned, it’s concerning that Microsoft’s CFO expects its quickly depreciating generative AI assets to monetize over 15 years. We’re in uncharted territory, hoping breakthrough applications that meaning contribute to clawing back capex will eventually justify these investments.
On Invest Like the Best, Gavin Baker painted a more concerning picture. He argues that hyperscaler CEOs are in a race to create a Digital God and shares Larry Page has said internally at Google that he’s “willing to go bankrupt rather than lose this race.” Companies like Google will keep spending until something tells them that scaling laws are slowing, and according to them, scaling laws have only slowed because NVIDIA chips haven’t improved since GPT-4 was released, and so one can deduce that capex will continue to grow… We don’t know if transformers will scale to the point of AGI, but in the minds of large companies, they better because that’s the only way any of this will end well financially. Sam was not tongue-in-cheek when he said that OpenAI’s business model was to create AGI and then ask how to return investor capital.
The premature rush to the AI endgame poses significant risks. We are massively over-indexing on an approach that shows diminishing returns, potentially at the cost of exploring more innovative and efficient paths to advanced reasoning. I am not saying that AI on its current trajectory isn’t insanely valuable, nor am I saying that the next lift provided by new chips will accelerate progress. I will even concede that if transformers were not the architecture of the future, then this isn’t all for naught as data centers can be repurposed. But this next shift will be similar to those of yesteryear. We may be over our skis. This cannot be the path to AGI.
A New Queen
Transformers excel at recognizing and reproducing patterns they’ve memorized from training data but struggle with tasks that require genuine reasoning. More training data does lead to better results on memorization-based benchmarks but offers only the illusion of general intelligence. Given the black box, it’s unclear whether more data improves reasoning or simply offers more potential patterns to be uncovered across contexts.
François Chollet offered a new benchmark in 2019 (formalized via a competition this summer) that shot to the forefront of the AI zeitgeist called Abstraction and Reasoning Corpus for Artificial General Intelligence, or ARC-AGI. In the prize announcement, the team states that scale will not enable LLMs to learn new skills. Instead, new generalizable architectures are needed to adapt to novel situations. ARC is designed to test an AI system’s ability to understand abstract patterns and apply that understanding to novel situations while explicitly resisting memorization, the core strength of transformers. Think of it like an IQ test, testing the purest form of “intelligence,” but for machines. The SOTA score to date on ARC is 46% from the MindsAI team led by Jack Cole. An 85% is needed to claim the $500K grand prize.
While we don’t know the methods of those atop the current leaderboard, I want to propose an intriguing potential solution: neurosymbolic AI (NSAI). This approach combines the best parts of self-supervised deep learning (pattern recognition and large-scale data retrieval) with symbolic approaches (explicit knowledge representation and logical reasoning), each making up for the other’s shortcomings.
A great comparison is that of Daniel Kahneman’s “Thinking Fast and Slow,” where neural nets represent system 1 thinking and symbolic AI system 2. From DeepMind:
Because language models excel at identifying general patterns and relationships in data, they can quickly predict potentially helpful constructs but cannot reason rigorously or explain their decisions. Symbolic deduction engines, on the other hand, are based on formal logic and use clear rules to arrive at conclusions. They are rational and explainable but can be slow and inflexible — especially when dealing with complex problems independently.
Subsymbolic (neural nets) and symbolic systems complement one another. While the former is robust against noise and excels at pattern recognition, symbolic systems thrive at tasks involving structured data and explicit reasoning. The challenge is reconciling the fundamentally different ways these systems represent information.
NSAI attempts to address this challenge by creating an integration that can leverage the strengths of both systems. Per Sheth et al., the integration of these can be broadly categorized across two main components:
- A neural component based on deep learning architectures can process raw, unstructured data and perform pattern recognition.
- A symbolic component that can handle knowledge representation, logical reasoning, and the manipulation of abstract concepts.
The team goes on to share that the actual integration can then be achieved through two approaches:
- Knowledge compression for neural integration involves techniques like knowledge graph embedding and logic-based compression.
- Neural pattern lifting for symbolic integration includes methods like decoupled and intertwined integration.
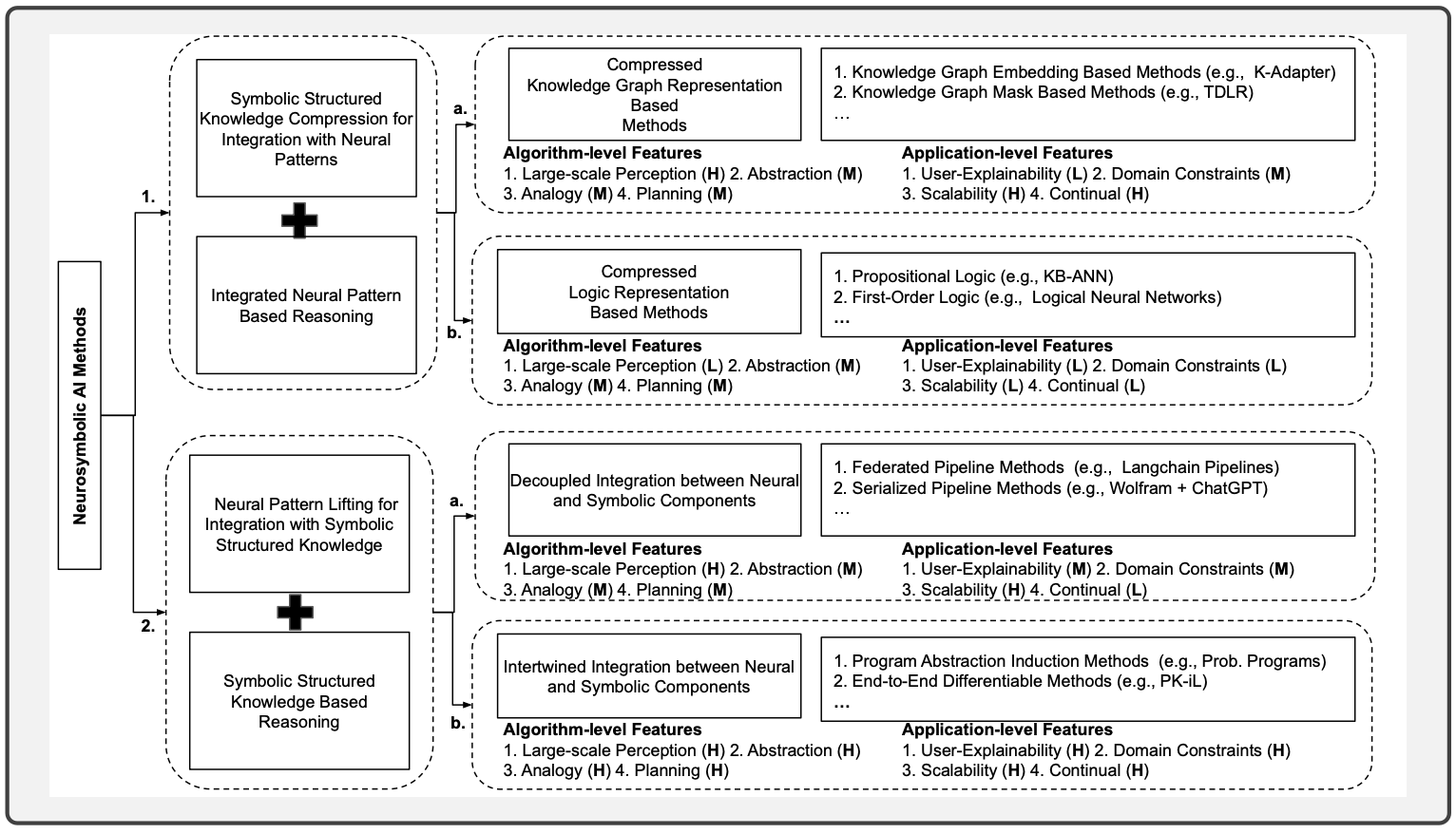 Neurosymbolic AI - Why, What, and How (Sheth et al.)
Neurosymbolic AI - Why, What, and How (Sheth et al.)
When compared to mainstream LLM architectures, NSAI offers manifold advantages. First is its enhanced reasoning and generalization capabilities. By incorporating oft-dismissed symbolic reasoning, these systems can generalize from fewer examples and apply knowledge more flexibly to new situations, precisely the kind of things ARC is testing for and where transformers fall short.
As a result, NSAI systems may require less training data to achieve higher performance, addressing one of the transformer’s fundamental limitations. This could democratize development, making it accessible to domains where large datasets are scarce or impossible to obtain. (Check out DisTrO from Nous Research for a snapshot of the future of more efficient LLM training.)
Unlike transformers’ black boxes, NSAI outputs are more transparent, offering a sort of audit trail for each step in the process. This transparency is critical for applications in nuanced fields where understanding the “why” is as important as the decision itself. This also helps better validate and corroborate outputs, reducing the likelihood of hallucination.
Finally, by incorporating neural nets into the winning architecture, we can build on the progress made over the past few years and build on top of what we already have. Human-level intelligence will use neural nets — just not rely on them entirely.
Looking forward, the potential applications of NSAI are vast, and integrating neural and symbolic approaches promises to compensate for the lost time and money (again, for some, not all) caused by transformers alone. However, realizing this potential will require sustained research effort and funding.
Luckily, we’re finally beginning to see NSAI approaches hit the mainstream. In January, DeepMind released AlphaGeometry, which can solve complex geometry problems at an International Mathematical Olympic Gold Medalist level. Its language model guides a symbolic deduction method towards the possible range of solutions. More recently, a company called Symbolica launched with $33M in funding. Symbolica is attempting to create a reasoning model via an approach rooted in category theory, which relates mathematical structures to one another. If you know anybody else making the emergence and adoption of NSAI their mission, please reach out.
We’ve reached a juncture in the AI wave, and it’s clear that the endgame has been called prematurely. Pieces have been sacrificed for perceived advantages as the industry has gone all-in on transformers and continues to blitzscale to beat the competition.
The transformer architecture (for all its impressive capabilities and economic importance) has fundamental flaws. The quadratic complexity problem has led to a series of incremental gambits that ultimately fail to solve the unsolvable. Spending in pursuit of the impossibly distant AGI has swelled to concerning levels. The disconnect between the numbers and the commentary raises serious questions about the long-term viability of this strategy.
Neurosymbolic AI does offer hope. By combining neural networks’ pattern recognition strengths with symbolic systems’ explicit reasoning capabilities, NSAI promises a more balanced and potentially fruitful approach to AGI. It’s still a pawn today, but as it marches down the board, it will soon become a queen to aid our beleaguered king.
The most successful chess players can adapt their strategy as the game evolves and see beyond the immediate tactics to the larger strategic picture. The same is true in AI research and AI itself. We must be willing to reconsider our opening moves, develop new strategies for the middlegame, and redefine what victory looks like in the endgame.
Additional Resources
There is so much more I could write on this topic. Check out the links throughout my write-up for frequently used resources. Below is a non-exhaustive list of additional papers that can help with technical context.
- A Neurosymbolic Approach to Adaptive Feature Extraction in SLAM (Chandio et al.)
- Automated programming, symbolic computation, machine learning: my personal view (Buchberger)
- Natural Language Processing and Neurosymbolic AI: The Role of Neural Networks with Knowledge-Guided Symbolic Approaches (Barnes, Hutson)
- Neuro-Symbolic AI: An Emerging Class of AI Workloads and their Characterization (Susskind et al)
- Neuro-symbolic approaches in artificial intelligence (Hitzler et al.)
- Neurosymbolic Programming (Chaudhuri et al.)
- Must-read papers from awesome-deeplogic
Acknowledgments
~ Thank you to Rohan Pujara for helping edit